
Our second AI Openness & Equity Policy Leadership cohort session centered around understanding the intention, value, and suitability of open source when applied to AI. Our discussions tackled a foundational question: What does “openness” mean in the age of AI, and how can the values of open-source guide AI systems to serve the public good? We were joined by Udbhav Tiwari from the Signal Foundation who brought an invaluable perspective to our discussion.

Image: Udbhav Tiwari
Our conversation was grounded around the definition of open source released by Open Source Initiative (OSI) in late 2024. The OSI definition has provided a basis for conversation about how the concept of open source can translate to AI, and it does not translate neatly. The definition is controversial in many “open” circles, and has faced criticism for lacking critical components such as requiring the data used in the training of AI systems to be disclosed and or distributed, ultimately leading some to worry that it caters too much to Big Tech industry players.
With this context, we first explored the technical and non-technical benefits of openness. Then, we unpacked the value of openness, highlighting that open source approaches on their own do not necessarily ensure transparency and accountability. Finally, we discussed how openness can be framed as a tool, and not a cure-all in the context of advancing accountable, equitable AI.
The following are some reflections and key takeaways from our conversation:
Technical and non-technical benefits of openness
By making code publicly available, open source software can function as a form of public interest technology. It empowers not just developers, but also people in civil society, research, policy and academia to examine and build on it. By doing so, such tools can deliver outcomes beyond just serving corporate interests.
Open source is often viewed as highly technical and “in the weeds”, which can make its benefits harder to see. This can lead some to question its value. But not all public goods need to serve everyone, all the time, to be important. Udhbav proposed nutrition labels as a useful analogy: if you don’t have food allergies or intolerances, those labels might seem irrelevant, yet they remain essential. Open source functions similarly. Even if you never actually read a line of code, its availability supports better transparency, oversight, and accountability.
Unpacking the value of openness
One of the most interesting threads in our discussions was the need to decouple open-source from benevolence. Understanding these nuances and the “why” behind an organisation or project’s decision to use open source is crucial to evaluating its value and contribution. In other words, just because something is open source, doesn’t make it a public interest contribution. There are many reasons — many of which are not for greater public engagement or accountability, or transparency — that an entity may opt for open source approaches. Often these decisions are shaped by factors like cutting costs, speeding up development through external collaborations, or gaining a competitive edge.
The group also discussed that in some contexts openness is always preferred, however in some cases full transparency can sometimes prove to be counterproductive. For example, publishing spam filter rules or adblocker lists can enable malicious actors to easily work around them. One participant raised the issue of how AI-generated porn, that disproportionately impacts marginalised communities, often relies on open source Large Language Models (LLMs). In such legitimate cases, full disclosure is not desirable, and openness may not be the best solution.
Openness as a tool, not a cure
While open source has historically been a powerful tool for enabling transparency and collaboration, it was developed in a very different era — one that doesn't fully account for today’s AI ecosystem. Simply applying open-source frameworks to AI doesn't guarantee public benefit. Udbhav offered a helpful lens to guide us: think of “open source” as technically meeting a legal or licensing category, and “openness” as something that exists on a gradient that includes practices like transparency, accessibility, the willingness to share knowledge, and collaborating widely. So, it’s not just about whether something meets a license requirement, but whether it is open enough to enable oversight and public scrutiny.
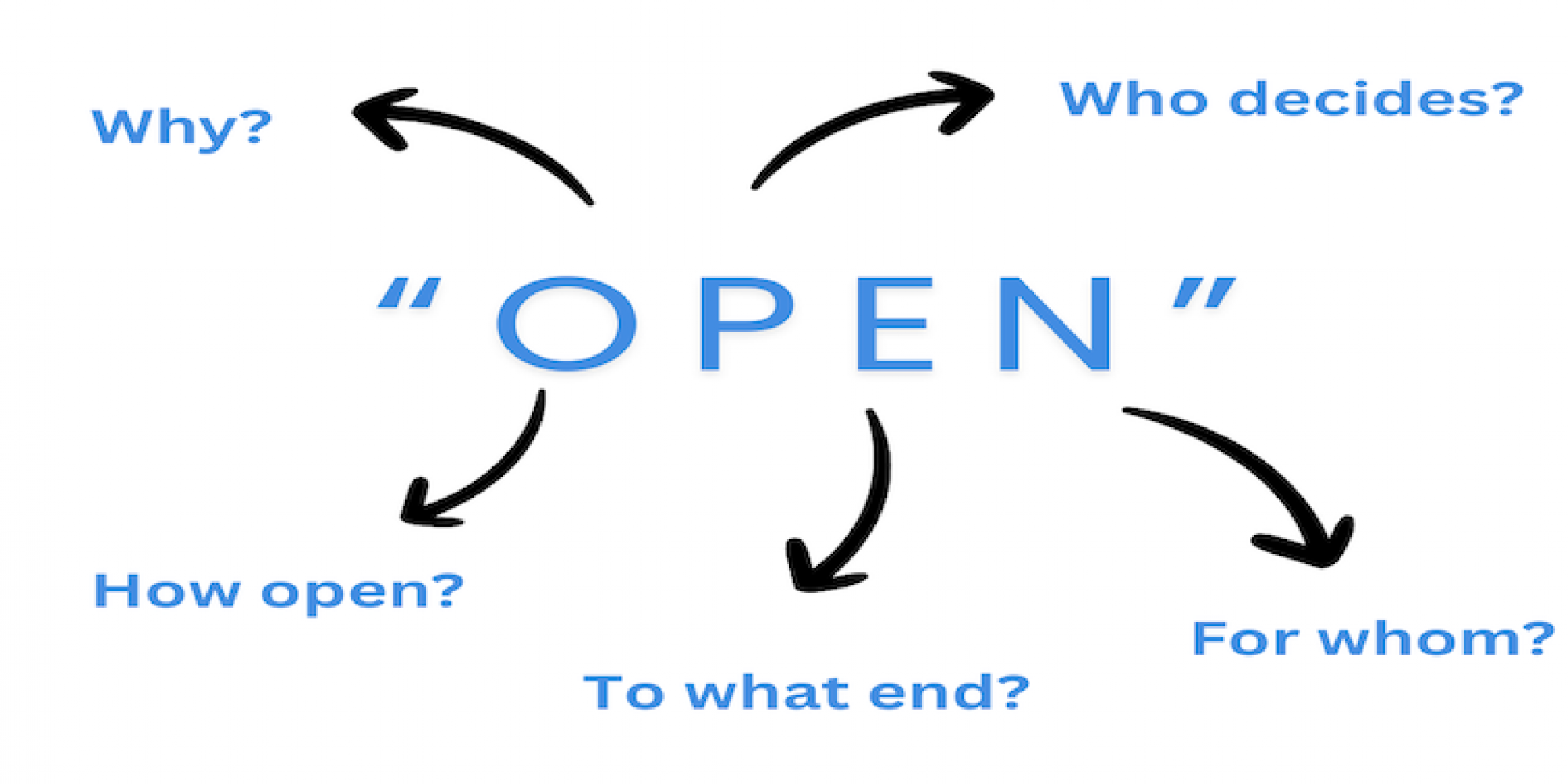
Open source does not give AI a free pass of providing openness for openness sake. It needs to prioritise public participation and equitable access for diverse communities to scrutinize and shape the technology. This is why it’s worth asking harder questions about what it means to be “open”, for whom, and to what end. Moving the conversation beyond binary thinking of “closed is bad” and “open is good” allows us to better assess whether openness is being used to genuinely serve the public interest, or merely open-washing.
The long road ahead…
We ended the session by grounding ourselves in our shared goal: a world where AI systems are rooted in equity and justice. The group reflected that while open source AI is often a necessary tool for achieving equity and justice in society, but is not sufficient on its own, nor is it a solution to the structural challenges posed by concentrated market power.
Open source values have historically supported reproducibility and collaboration: anyone can take code, adapt it, and build on it. But with AI, especially when it comes to training data, the picture is more complex. Key questions remain about how openness and equity can - and should be - applied to AI systems. How to treat these questions, particularly around data, if openness is to translate more meaningfully and fully to AI? What does accountable openness look like in this context, and how can it serve the public interest?
These are the hard questions that we will continue tackling in future sessions. We will also deepen our thinking on what “Public AI” could and should be, examine how security and openness go hand in hand, and grapple with the intersection of AI and climate justice accountability. These insights will inform the practical recommendations we are developing to support better policymaking in the age of AI.
More soon!
This blog post was co-written by Nitya Kuthiala.